Deep Convolutional Inverse Graphics Network 算法数据

 |
|  197 |
197 |  0 |
0 |  0
0



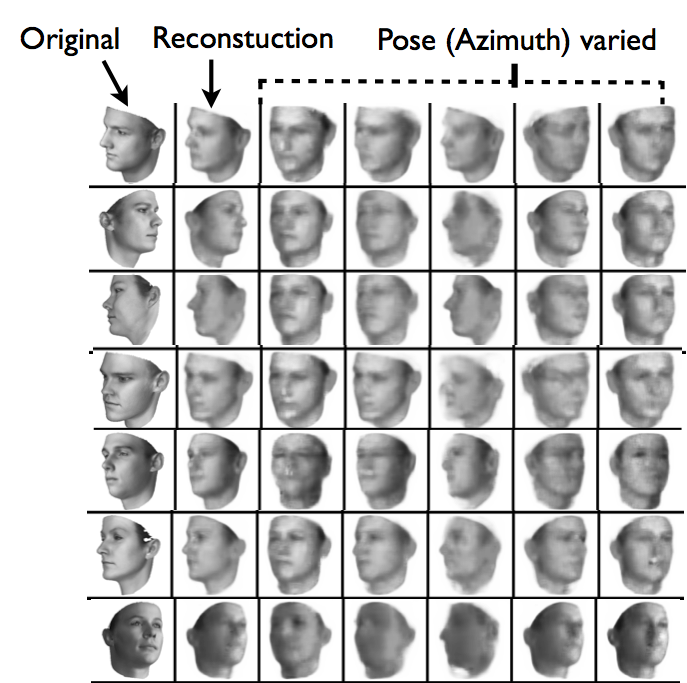

Demo of our model re-rendering a given static image with different 3D sweeps on (a) elevation and (b) azimuth and (c) light neurons.

Deep Convolutional Inverse Graphics Network (DC-IGN) has an encoder and a decoder. We follow the variational autoencoder (Kingma and Welling) architecture with several variations. The encoder consists of several layers of convolutions followed by max-pooling and the decoder has several layers of unpooling (upsampling using nearest neighbors) followed by convolution. (a) During training, data (x) is passed through the encoder to produce the posterior approximation Q(z_i|x), where z_i consists of scene latent variables such as pose, light, texture or shape. In order to learn parameters in DC-IGN, gradients are backpropagated using stochastic gradient descent using the following variational object function: -log(P(x|z_i)) + KL(Q(z_i|x)||P(z_i)) for every z_i. We can force DC-IGN to learn a disentangled representation by showing mini-batches with a set of inactive and active transformations (eg face rotating, light sweeping in some direction etc). (b) During test, data x can be passed through the encoder to get latents z_i. Images can be re-rendered to different viewpoints, lighting conditions, shape variations etc by just manipulating the appropriate graphics code group (z_i), which is how one would manipulate an off the shelf 3D graphics engine.

还没有评论,说两句吧!
热门资源

GRAZ 图像分类数据
GRAZ 图像分类数据

猫和狗图像分类数...
Kaggle 上的竞赛数据,用以区分猫和狗两类对象,...

Large Scale Data FTP
Large Scale Data FTP

MIT Cars 汽车图像...
MIT Cars 汽车图像数据

凶杀案报告数据
凶杀案报告数据


智能在线
400-630-6780

聆听.建议反馈
E-mail: support@tusaishared.com

 资源分类
资源分类


