pytorch-unet

 |
|  53 |
53 |  0 |
0 |  0
0



This repository contains simple PyTorch implementations of U-Net and FCN, which are deep learning segmentation methods proposed by Ronneberger et al. and Long et al.
First clone the repository and cd into the project directory.
import matplotlib.pyplot as pltimport numpy as npimport helperimport simulation# Generate some random imagesinput_images, target_masks = simulation.generate_random_data(192, 192, count=3)for x in [input_images, target_masks]: print(x.shape) print(x.min(), x.max())# Change channel-order and make 3 channels for matplotinput_images_rgb = [x.astype(np.uint8) for x in input_images]# Map each channel (i.e. class) to each colortarget_masks_rgb = [helper.masks_to_colorimg(x) for x in target_masks]# Left: Input image (black and white), Right: Target mask (6ch)helper.plot_side_by_side([input_images_rgb, target_masks_rgb])
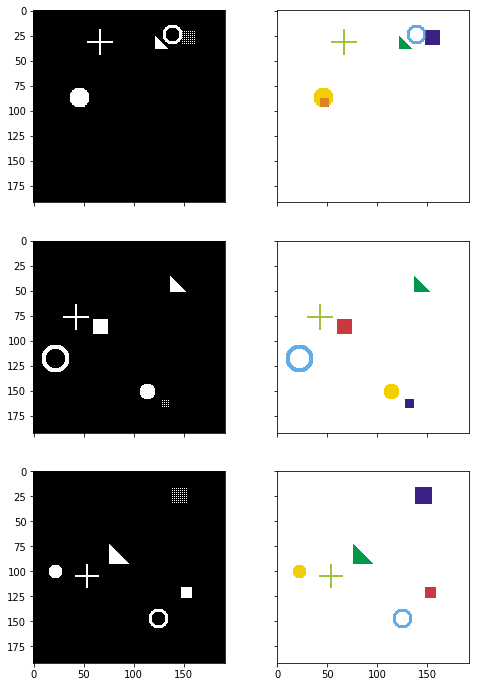
from torch.utils.data import Dataset, DataLoaderfrom torchvision import transforms, datasets, modelsclass SimDataset(Dataset): def __init__(self, count, transform=None): self.input_images, self.target_masks = simulation.generate_random_data(192, 192, count=count) self.transform = transform def __len__(self): return len(self.input_images) def __getitem__(self, idx):
image = self.input_images[idx]
mask = self.target_masks[idx] if self.transform:
image = self.transform(image) return [image, mask]# use the same transformations for train/val in this exampletrans = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # imagenet])
train_set = SimDataset(2000, transform = trans)
val_set = SimDataset(200, transform = trans)
image_datasets = { 'train': train_set, 'val': val_set
}
batch_size = 25dataloaders = { 'train': DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0), 'val': DataLoader(val_set, batch_size=batch_size, shuffle=True, num_workers=0)
}import torchvision.utilsdef reverse_transform(inp): inp = inp.numpy().transpose((1, 2, 0)) mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) inp = std * inp + mean inp = np.clip(inp, 0, 1) inp = (inp * 255).astype(np.uint8) return inp# Get a batch of training datainputs, masks = next(iter(dataloaders['train']))print(inputs.shape, masks.shape) plt.imshow(reverse_transform(inputs[3]))
torch.Size([25, 3, 192, 192]) torch.Size([25, 6, 192, 192])

import torchimport torch.nn as nnfrom torchvision import modelsdef convrelu(in_channels, out_channels, kernel, padding): return nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel, padding=padding), nn.ReLU(inplace=True), )class ResNetUNet(nn.Module): def __init__(self, n_class): super().__init__() self.base_model = models.resnet18(pretrained=True) self.base_layers = list(self.base_model.children()) self.layer0 = nn.Sequential(*self.base_layers[:3]) # size=(N, 64, x.H/2, x.W/2) self.layer0_1x1 = convrelu(64, 64, 1, 0) self.layer1 = nn.Sequential(*self.base_layers[3:5]) # size=(N, 64, x.H/4, x.W/4) self.layer1_1x1 = convrelu(64, 64, 1, 0) self.layer2 = self.base_layers[5] # size=(N, 128, x.H/8, x.W/8) self.layer2_1x1 = convrelu(128, 128, 1, 0) self.layer3 = self.base_layers[6] # size=(N, 256, x.H/16, x.W/16) self.layer3_1x1 = convrelu(256, 256, 1, 0) self.layer4 = self.base_layers[7] # size=(N, 512, x.H/32, x.W/32) self.layer4_1x1 = convrelu(512, 512, 1, 0) self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True) self.conv_up3 = convrelu(256 + 512, 512, 3, 1) self.conv_up2 = convrelu(128 + 512, 256, 3, 1) self.conv_up1 = convrelu(64 + 256, 256, 3, 1) self.conv_up0 = convrelu(64 + 256, 128, 3, 1) self.conv_original_size0 = convrelu(3, 64, 3, 1) self.conv_original_size1 = convrelu(64, 64, 3, 1) self.conv_original_size2 = convrelu(64 + 128, 64, 3, 1) self.conv_last = nn.Conv2d(64, n_class, 1) def forward(self, input): x_original = self.conv_original_size0(input) x_original = self.conv_original_size1(x_original) layer0 = self.layer0(input) layer1 = self.layer1(layer0) layer2 = self.layer2(layer1) layer3 = self.layer3(layer2) layer4 = self.layer4(layer3) layer4 = self.layer4_1x1(layer4) x = self.upsample(layer4) layer3 = self.layer3_1x1(layer3) x = torch.cat([x, layer3], dim=1) x = self.conv_up3(x) x = self.upsample(x) layer2 = self.layer2_1x1(layer2) x = torch.cat([x, layer2], dim=1) x = self.conv_up2(x) x = self.upsample(x) layer1 = self.layer1_1x1(layer1) x = torch.cat([x, layer1], dim=1) x = self.conv_up1(x) x = self.upsample(x) layer0 = self.layer0_1x1(layer0) x = torch.cat([x, layer0], dim=1) x = self.conv_up0(x) x = self.upsample(x) x = torch.cat([x, x_original], dim=1) x = self.conv_original_size2(x) out = self.conv_last(x) return out
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ResNetUNet(n_class=6)
model = model.to(device)# check keras-like model summary using torchsummaryfrom torchsummary import summary
summary(model, input_size=(3, 224, 224))---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 64, 224, 224] 1,792 ReLU-2 [-1, 64, 224, 224] 0 Conv2d-3 [-1, 64, 224, 224] 36,928 ReLU-4 [-1, 64, 224, 224] 0 Conv2d-5 [-1, 64, 112, 112] 9,408 BatchNorm2d-6 [-1, 64, 112, 112] 128 ReLU-7 [-1, 64, 112, 112] 0 MaxPool2d-8 [-1, 64, 56, 56] 0 Conv2d-9 [-1, 64, 56, 56] 4,096 BatchNorm2d-10 [-1, 64, 56, 56] 128 ReLU-11 [-1, 64, 56, 56] 0 Conv2d-12 [-1, 64, 56, 56] 36,864 BatchNorm2d-13 [-1, 64, 56, 56] 128 ReLU-14 [-1, 64, 56, 56] 0 Conv2d-15 [-1, 256, 56, 56] 16,384 BatchNorm2d-16 [-1, 256, 56, 56] 512 Conv2d-17 [-1, 256, 56, 56] 16,384 BatchNorm2d-18 [-1, 256, 56, 56] 512 ReLU-19 [-1, 256, 56, 56] 0 Bottleneck-20 [-1, 256, 56, 56] 0 Conv2d-21 [-1, 64, 56, 56] 16,384 BatchNorm2d-22 [-1, 64, 56, 56] 128 ReLU-23 [-1, 64, 56, 56] 0 Conv2d-24 [-1, 64, 56, 56] 36,864 BatchNorm2d-25 [-1, 64, 56, 56] 128 ReLU-26 [-1, 64, 56, 56] 0 Conv2d-27 [-1, 256, 56, 56] 16,384 BatchNorm2d-28 [-1, 256, 56, 56] 512 ReLU-29 [-1, 256, 56, 56] 0 Bottleneck-30 [-1, 256, 56, 56] 0 Conv2d-31 [-1, 64, 56, 56] 16,384 BatchNorm2d-32 [-1, 64, 56, 56] 128 ReLU-33 [-1, 64, 56, 56] 0 Conv2d-34 [-1, 64, 56, 56] 36,864 BatchNorm2d-35 [-1, 64, 56, 56] 128 ReLU-36 [-1, 64, 56, 56] 0 Conv2d-37 [-1, 256, 56, 56] 16,384 BatchNorm2d-38 [-1, 256, 56, 56] 512 ReLU-39 [-1, 256, 56, 56] 0 Bottleneck-40 [-1, 256, 56, 56] 0 Conv2d-41 [-1, 128, 56, 56] 32,768 BatchNorm2d-42 [-1, 128, 56, 56] 256 ReLU-43 [-1, 128, 56, 56] 0 Conv2d-44 [-1, 128, 28, 28] 147,456 BatchNorm2d-45 [-1, 128, 28, 28] 256 ReLU-46 [-1, 128, 28, 28] 0 Conv2d-47 [-1, 512, 28, 28] 65,536 BatchNorm2d-48 [-1, 512, 28, 28] 1,024 Conv2d-49 [-1, 512, 28, 28] 131,072 BatchNorm2d-50 [-1, 512, 28, 28] 1,024 ReLU-51 [-1, 512, 28, 28] 0 Bottleneck-52 [-1, 512, 28, 28] 0 Conv2d-53 [-1, 128, 28, 28] 65,536 BatchNorm2d-54 [-1, 128, 28, 28] 256 ReLU-55 [-1, 128, 28, 28] 0 Conv2d-56 [-1, 128, 28, 28] 147,456 BatchNorm2d-57 [-1, 128, 28, 28] 256 ReLU-58 [-1, 128, 28, 28] 0 Conv2d-59 [-1, 512, 28, 28] 65,536 BatchNorm2d-60 [-1, 512, 28, 28] 1,024 ReLU-61 [-1, 512, 28, 28] 0 Bottleneck-62 [-1, 512, 28, 28] 0 Conv2d-63 [-1, 128, 28, 28] 65,536 BatchNorm2d-64 [-1, 128, 28, 28] 256 ReLU-65 [-1, 128, 28, 28] 0 Conv2d-66 [-1, 128, 28, 28] 147,456 BatchNorm2d-67 [-1, 128, 28, 28] 256 ReLU-68 [-1, 128, 28, 28] 0 Conv2d-69 [-1, 512, 28, 28] 65,536 BatchNorm2d-70 [-1, 512, 28, 28] 1,024 ReLU-71 [-1, 512, 28, 28] 0 Bottleneck-72 [-1, 512, 28, 28] 0 Conv2d-73 [-1, 128, 28, 28] 65,536 BatchNorm2d-74 [-1, 128, 28, 28] 256 ReLU-75 [-1, 128, 28, 28] 0 Conv2d-76 [-1, 128, 28, 28] 147,456 BatchNorm2d-77 [-1, 128, 28, 28] 256 ReLU-78 [-1, 128, 28, 28] 0 Conv2d-79 [-1, 512, 28, 28] 65,536 BatchNorm2d-80 [-1, 512, 28, 28] 1,024 ReLU-81 [-1, 512, 28, 28] 0 Bottleneck-82 [-1, 512, 28, 28] 0 Conv2d-83 [-1, 256, 28, 28] 131,072 BatchNorm2d-84 [-1, 256, 28, 28] 512 ReLU-85 [-1, 256, 28, 28] 0 Conv2d-86 [-1, 256, 14, 14] 589,824 BatchNorm2d-87 [-1, 256, 14, 14] 512 ReLU-88 [-1, 256, 14, 14] 0 Conv2d-89 [-1, 1024, 14, 14] 262,144 BatchNorm2d-90 [-1, 1024, 14, 14] 2,048 Conv2d-91 [-1, 1024, 14, 14] 524,288 BatchNorm2d-92 [-1, 1024, 14, 14] 2,048 ReLU-93 [-1, 1024, 14, 14] 0 Bottleneck-94 [-1, 1024, 14, 14] 0 Conv2d-95 [-1, 256, 14, 14] 262,144 BatchNorm2d-96 [-1, 256, 14, 14] 512 ReLU-97 [-1, 256, 14, 14] 0 Conv2d-98 [-1, 256, 14, 14] 589,824 BatchNorm2d-99 [-1, 256, 14, 14] 512 ReLU-100 [-1, 256, 14, 14] 0 Conv2d-101 [-1, 1024, 14, 14] 262,144 BatchNorm2d-102 [-1, 1024, 14, 14] 2,048 ReLU-103 [-1, 1024, 14, 14] 0 Bottleneck-104 [-1, 1024, 14, 14] 0 Conv2d-105 [-1, 256, 14, 14] 262,144 BatchNorm2d-106 [-1, 256, 14, 14] 512 ReLU-107 [-1, 256, 14, 14] 0 Conv2d-108 [-1, 256, 14, 14] 589,824 BatchNorm2d-109 [-1, 256, 14, 14] 512 ReLU-110 [-1, 256, 14, 14] 0 Conv2d-111 [-1, 1024, 14, 14] 262,144 BatchNorm2d-112 [-1, 1024, 14, 14] 2,048 ReLU-113 [-1, 1024, 14, 14] 0 Bottleneck-114 [-1, 1024, 14, 14] 0 Conv2d-115 [-1, 256, 14, 14] 262,144 BatchNorm2d-116 [-1, 256, 14, 14] 512 ReLU-117 [-1, 256, 14, 14] 0 Conv2d-118 [-1, 256, 14, 14] 589,824 BatchNorm2d-119 [-1, 256, 14, 14] 512 ReLU-120 [-1, 256, 14, 14] 0 Conv2d-121 [-1, 1024, 14, 14] 262,144 BatchNorm2d-122 [-1, 1024, 14, 14] 2,048 ReLU-123 [-1, 1024, 14, 14] 0 Bottleneck-124 [-1, 1024, 14, 14] 0 Conv2d-125 [-1, 256, 14, 14] 262,144 BatchNorm2d-126 [-1, 256, 14, 14] 512 ReLU-127 [-1, 256, 14, 14] 0 Conv2d-128 [-1, 256, 14, 14] 589,824 BatchNorm2d-129 [-1, 256, 14, 14] 512 ReLU-130 [-1, 256, 14, 14] 0 Conv2d-131 [-1, 1024, 14, 14] 262,144 BatchNorm2d-132 [-1, 1024, 14, 14] 2,048 ReLU-133 [-1, 1024, 14, 14] 0 Bottleneck-134 [-1, 1024, 14, 14] 0 Conv2d-135 [-1, 256, 14, 14] 262,144 BatchNorm2d-136 [-1, 256, 14, 14] 512 ReLU-137 [-1, 256, 14, 14] 0 Conv2d-138 [-1, 256, 14, 14] 589,824 BatchNorm2d-139 [-1, 256, 14, 14] 512 ReLU-140 [-1, 256, 14, 14] 0 Conv2d-141 [-1, 1024, 14, 14] 262,144 BatchNorm2d-142 [-1, 1024, 14, 14] 2,048 ReLU-143 [-1, 1024, 14, 14] 0 Bottleneck-144 [-1, 1024, 14, 14] 0 Conv2d-145 [-1, 512, 14, 14] 524,288 BatchNorm2d-146 [-1, 512, 14, 14] 1,024 ReLU-147 [-1, 512, 14, 14] 0 Conv2d-148 [-1, 512, 7, 7] 2,359,296 BatchNorm2d-149 [-1, 512, 7, 7] 1,024 ReLU-150 [-1, 512, 7, 7] 0 Conv2d-151 [-1, 2048, 7, 7] 1,048,576 BatchNorm2d-152 [-1, 2048, 7, 7] 4,096 Conv2d-153 [-1, 2048, 7, 7] 2,097,152 BatchNorm2d-154 [-1, 2048, 7, 7] 4,096 ReLU-155 [-1, 2048, 7, 7] 0 Bottleneck-156 [-1, 2048, 7, 7] 0 Conv2d-157 [-1, 512, 7, 7] 1,048,576 BatchNorm2d-158 [-1, 512, 7, 7] 1,024 ReLU-159 [-1, 512, 7, 7] 0 Conv2d-160 [-1, 512, 7, 7] 2,359,296 BatchNorm2d-161 [-1, 512, 7, 7] 1,024 ReLU-162 [-1, 512, 7, 7] 0 Conv2d-163 [-1, 2048, 7, 7] 1,048,576 BatchNorm2d-164 [-1, 2048, 7, 7] 4,096 ReLU-165 [-1, 2048, 7, 7] 0 Bottleneck-166 [-1, 2048, 7, 7] 0 Conv2d-167 [-1, 512, 7, 7] 1,048,576 BatchNorm2d-168 [-1, 512, 7, 7] 1,024 ReLU-169 [-1, 512, 7, 7] 0 Conv2d-170 [-1, 512, 7, 7] 2,359,296 BatchNorm2d-171 [-1, 512, 7, 7] 1,024 ReLU-172 [-1, 512, 7, 7] 0 Conv2d-173 [-1, 2048, 7, 7] 1,048,576 BatchNorm2d-174 [-1, 2048, 7, 7] 4,096 ReLU-175 [-1, 2048, 7, 7] 0 Bottleneck-176 [-1, 2048, 7, 7] 0 Conv2d-177 [-1, 1024, 7, 7] 2,098,176 ReLU-178 [-1, 1024, 7, 7] 0 Upsample-179 [-1, 1024, 14, 14] 0 Conv2d-180 [-1, 512, 14, 14] 524,800 ReLU-181 [-1, 512, 14, 14] 0 Conv2d-182 [-1, 512, 14, 14] 7,078,400 ReLU-183 [-1, 512, 14, 14] 0 Upsample-184 [-1, 512, 28, 28] 0 Conv2d-185 [-1, 512, 28, 28] 262,656 ReLU-186 [-1, 512, 28, 28] 0 Conv2d-187 [-1, 512, 28, 28] 4,719,104 ReLU-188 [-1, 512, 28, 28] 0 Upsample-189 [-1, 512, 56, 56] 0 Conv2d-190 [-1, 256, 56, 56] 65,792 ReLU-191 [-1, 256, 56, 56] 0 Conv2d-192 [-1, 256, 56, 56] 1,769,728 ReLU-193 [-1, 256, 56, 56] 0 Upsample-194 [-1, 256, 112, 112] 0 Conv2d-195 [-1, 64, 112, 112] 4,160 ReLU-196 [-1, 64, 112, 112] 0 Conv2d-197 [-1, 128, 112, 112] 368,768 ReLU-198 [-1, 128, 112, 112] 0 Upsample-199 [-1, 128, 224, 224] 0 Conv2d-200 [-1, 64, 224, 224] 110,656 ReLU-201 [-1, 64, 224, 224] 0 Conv2d-202 [-1, 6, 224, 224] 390 ================================================================ Total params: 40,549,382 Trainable params: 40,549,382 Non-trainable params: 0 ----------------------------------------------------------------
from collections import defaultdictimport torch.nn.functional as Ffrom loss import dice_lossdef calc_loss(pred, target, metrics, bce_weight=0.5):
bce = F.binary_cross_entropy_with_logits(pred, target)
pred = F.sigmoid(pred)
dice = dice_loss(pred, target)
loss = bce * bce_weight + dice * (1 - bce_weight)
metrics['bce'] += bce.data.cpu().numpy() * target.size(0)
metrics['dice'] += dice.data.cpu().numpy() * target.size(0)
metrics['loss'] += loss.data.cpu().numpy() * target.size(0) return lossdef print_metrics(metrics, epoch_samples, phase):
outputs = [] for k in metrics.keys():
outputs.append("{}: {:4f}".format(k, metrics[k] / epoch_samples)) print("{}: {}".format(phase, ", ".join(outputs)))def train_model(model, optimizer, scheduler, num_epochs=25):
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = 1e10
for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch, num_epochs - 1)) print('-' * 10)
since = time.time() # Each epoch has a training and validation phase
for phase in ['train', 'val']: if phase == 'train':
scheduler.step() for param_group in optimizer.param_groups: print("LR", param_group['lr'])
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
metrics = defaultdict(float)
epoch_samples = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device) # zero the parameter gradients
optimizer.zero_grad() # forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
loss = calc_loss(outputs, labels, metrics) # backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step() # statistics
epoch_samples += inputs.size(0)
print_metrics(metrics, epoch_samples, phase)
epoch_loss = metrics['loss'] / epoch_samples # deep copy the model
if phase == 'val' and epoch_loss < best_loss: print("saving best model")
best_loss = epoch_loss
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since print('{:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60)) print('Best val loss: {:4f}'.format(best_loss)) # load best model weights
model.load_state_dict(best_model_wts) return modelimport torchimport torch.optim as optimfrom torch.optim import lr_schedulerimport timeimport copy
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print(device)
num_class = 6model = ResNetUNet(num_class).to(device)# freeze backbone layers#for l in model.base_layers:# for param in l.parameters():# param.requires_grad = Falseoptimizer_ft = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-4)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=30, gamma=0.1)
model = train_model(model, optimizer_ft, exp_lr_scheduler, num_epochs=60)cuda:0 Epoch 0/59 ---------- LR 0.0001 train: bce: 0.070256, dice: 0.856320, loss: 0.463288 val: bce: 0.014897, dice: 0.515814, loss: 0.265356 saving best model 0m 51s Epoch 1/59 ---------- LR 0.0001 train: bce: 0.011369, dice: 0.309445, loss: 0.160407 val: bce: 0.003790, dice: 0.113682, loss: 0.058736 saving best model 0m 51s Epoch 2/59 ---------- LR 0.0001 train: bce: 0.003480, dice: 0.089928, loss: 0.046704 val: bce: 0.002525, dice: 0.067604, loss: 0.035064 saving best model 0m 51s (Omitted) Epoch 57/59 ---------- LR 1e-05 train: bce: 0.000523, dice: 0.010289, loss: 0.005406 val: bce: 0.001558, dice: 0.030965, loss: 0.016261 0m 51s Epoch 58/59 ---------- LR 1e-05 train: bce: 0.000518, dice: 0.010209, loss: 0.005364 val: bce: 0.001548, dice: 0.031034, loss: 0.016291 0m 51s Epoch 59/59 ---------- LR 1e-05 train: bce: 0.000518, dice: 0.010168, loss: 0.005343 val: bce: 0.001566, dice: 0.030785, loss: 0.016176 0m 50s Best val loss: 0.016171
import math model.eval() # Set model to the evaluation mode# Create another simulation dataset for testtest_dataset = SimDataset(3, transform = trans) test_loader = DataLoader(test_dataset, batch_size=3, shuffle=False, num_workers=0)# Get the first batchinputs, labels = next(iter(test_loader)) inputs = inputs.to(device) labels = labels.to(device)# Predictpred = model(inputs)# The loss functions include the sigmoid function.pred = F.sigmoid(pred) pred = pred.data.cpu().numpy()print(pred.shape)# Change channel-order and make 3 channels for matplotinput_images_rgb = [reverse_transform(x) for x in inputs.cpu()]# Map each channel (i.e. class) to each colortarget_masks_rgb = [helper.masks_to_colorimg(x) for x in labels.cpu().numpy()] pred_rgb = [helper.masks_to_colorimg(x) for x in pred] helper.plot_side_by_side([input_images_rgb, target_masks_rgb, pred_rgb])
(3, 6, 192, 192)
还没有评论,说两句吧!
热门资源

Keras-ResNeXt
Keras ResNeXt Implementation of ResNeXt models...

seetafaceJNI
项目介绍 基于中科院seetaface2进行封装的JAVA...

spark-corenlp
This package wraps Stanford CoreNLP annotators ...

capsnet-with-caps...
CapsNet with capsule-wise convolution Project ...

inferno-boilerplate
This is a very basic boilerplate example for pe...


智能在线
400-630-6780

聆听.建议反馈
E-mail: support@tusaishared.com

 资源分类
资源分类


