AGE

 |
|  244 |
244 |  0 |
0 |  0
0



This repository contains code for the paper
"Adversarial Generator-Encoder Networks" by Dmitry Ulyanov, Andrea Vedaldi, Victor Lempitsky.
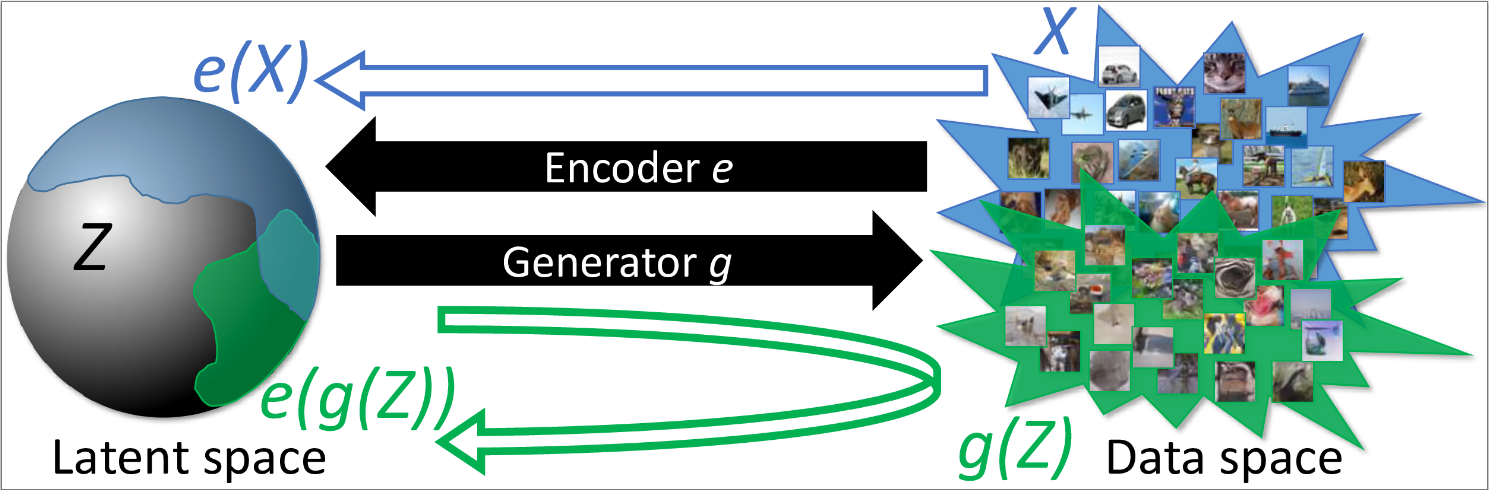
This is how you can access the models used to generate figures in the paper.
1) First install dev version of pyTorch (see manual here) and make sure you have jupyter notebook ready.
2) Then download the models with the script:
bash download_pretrained.sh
3) Run jupyter notebook and go through evaluate.ipynb.
Here is an example of samples and reconstructions for imagenet, celeba and cifar10 datasets generated with evaluate.ipynb.
|Samples |Reconstructions| |:---------:|:-------------:| | |
|  |
|
|Samples |Reconstructions| |:---------:|:-------------:| | |
|  |
|
|Samples |Reconstructions| |:---------:|:-------------:| | |
|  |
|
Use age.py script to train a model. Here are the most important parameters:
--dataset: one of [celeba, cifar10, imagenet, svhn, mnist]
--dataroot: for datasets included in torchvision it is a directory where everything will be downloaded to; for imagenet, celeba datasets it is a path to a directory with folders train and val inside.
--image_size:
--save_dir: path to a folder, where checkpoints will be stored
--nz: dimensionality of latent space
-- batch_size: Batch size. Default 64.
--netG: .py file with generator definition. Searched in models directory
--netE: .py file with generator definition. Searched in models directory
--netG_chp: path to a generator checkpoint to load from
--netE_chp: path to an encoder checkpoint to load from
--nepoch: number of epoch to run
--start_epoch: epoch number to start from. Useful for finetuning.
--e_updates: Update plan for encoder. <num steps>;KL_fake:<weight>,KL_real:<weight>,match_z:<weight>,match_x:<weight>.
--g_updates: Update plan for generator. <num steps>;KL_fake:<weight>,match_z:<weight>,match_x:<weight>.
And misc arguments: * --workers: number of dataloader workers. * --ngf: controlles number of channels in generator * --ndf: controlles number of channels in encoder * --beta1: parameter for ADAM optimizer * --cpu: do not use GPU * --criterion: Parametric param or non-parametric nonparam way to compute KL. Parametric fits Gaussian into data, non-parametric is based on nearest neighbors. Default: param. * --KL: What KL to compute: qp or pq. Default is qp. * --noise: sphere for uniform on sphere or gaussian. Default sphere. * --match_z: loss to use as reconstruction loss in latent space. L1|L2|cos. Default cos. * --match_x: loss to use as reconstruction loss in data space. L1|L2|cos. Default L1. * --drop_lr: each drop_lr epochs a learning rate is dropped. * --save_every: controls how often intermediate results are stored. Default 50. * --manual_seed: random seed. Default 123.
Here is cmd you can start with:
Let data_root to be a directory with two folders train, val, each with the images for corresponding split.
python age.py --dataset celeba --dataroot <data_root> --image_size 64 --save_dir <save_dir> --lr 0.0002 --nz 64 --batch_size 64 --netG dcgan64px --netE dcgan64px --nepoch 5 --drop_lr 5 --e_updates '1;KL_fake:1,KL_real:1,match_z:0,match_x:10' --g_updates '3;KL_fake:1,match_z:1000,match_x:0'
It is beneficial to finetune the model with larger batch_size and stronger matching weight then:
python age.py --dataset celeba --dataroot <data_root> --image_size 64 --save_dir <save_dir> --start_epoch 5 --lr 0.0002 --nz 64 --batch_size 256 --netG dcgan64px --netE dcgan64px --nepoch 6 --drop_lr 5 --e_updates '1;KL_fake:1,KL_real:1,match_z:0,match_x:15' --g_updates '3;KL_fake:1,match_z:1000,match_x:0' --netE_chp <save_dir>/netE_epoch_5.pth --netG_chp <save_dir>/netG_epoch_5.pth
python age.py --dataset imagenet --dataroot /path/to/imagenet_dir/ --save_dir <save_dir> --image_size 32 --save_dir ${pdir} --lr 0.0002 --nz 128 --netG dcgan32px --netE dcgan32px --nepoch 6 --drop_lr 3 --e_updates '1;KL_fake:1,KL_real:1,match_z:0,match_x:10' --g_updates '2;KL_fake:1,match_z:2000,match_x:0' --workers 12It can be beneficial to switch to 256 batch size after several epochs.
python age.py --dataset cifar10 --image_size 32 --save_dir <save_dir> --lr 0.0002 --nz 128 --netG dcgan32px --netE dcgan32px --nepoch 150 --drop_lr 40 --e_updates '1;KL_fake:1,KL_real:1,match_z:0,match_x:10' --g_updates '2;KL_fake:1,match_z:1000,match_x:0'
Tested with python 2.7.
Implementation is based on pyTorch DCGAN code.
If you found this code useful please cite our paper
@article{ulyanov2017age,
title={Adversarial Generator-Encoder Networks},
author={Ulyanov, Dmitry and Vedaldi, Andrea and Lempitsky, Victor},
journal={arXiv preprint arXiv:1704.02304},
year={2017}
}
还没有评论,说两句吧!
热门资源

allennlp-server
allennlp-server Serve allennlp services as sep...

ubuntu-allennlp
ubuntu-allennlp AllenAI AllenNLP image based o...

allennlp_extras
allennlp_extras Some utilities build on top of...

allennlp-dureader
An Apache 2.0 NLP research library, built on Py...

seetafaceJNI
项目介绍 基于中科院seetaface2进行封装的JAVA...


智能在线
400-630-6780

聆听.建议反馈
E-mail: support@tusaishared.com

 资源分类
资源分类


