Loop

 |
|  300 |
300 |  0 |
0 |  0
0



PyTorch实现了VoiceLoop:Voice Fitting and Synthesis via Phonological Loop中描述的方法。
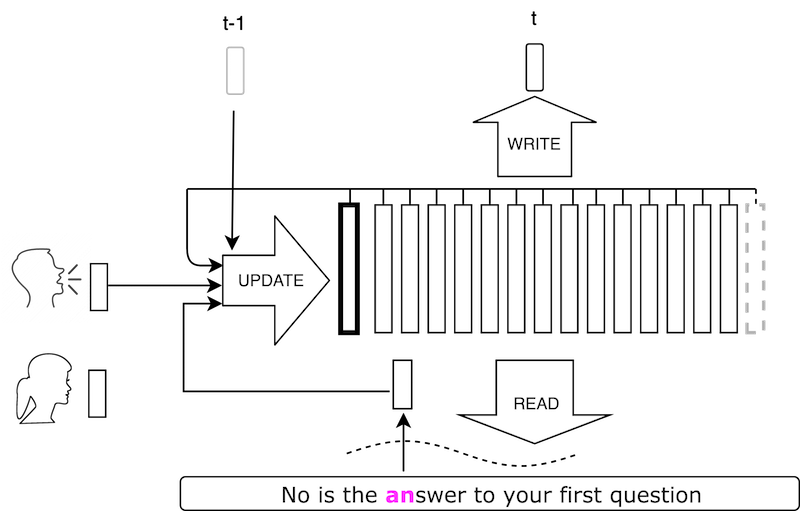
VoiceLoop是一种神经文本到语音(TTS),能够在野外采样的语音中将文本转换为语音。一些演示样本可以在这里找到。
按照安装程序中的说明操作,然后执行: bash
python generate.py --npz data/vctk/numpy_features_valid/p318_212.npz --spkr 13 --checkpoint models/vctk/bestmodel.pth
结果将被放入models/vctk/results。它将生成2个样本:* 生成的样本将以gen_10.wav扩展名保存。*它的地面实况(测试)样本也会生成,并使用orig.wav扩展名保存。
您也可以使用不同的扬声器生成相同的文本,具体为: bash
python generate.py --npz data/vctk/numpy_features_valid/p318_212.npz --spkr 18 --checkpoint models/vctk/bestmodel.pth将生成以下示例。
这是相应的注意情节:
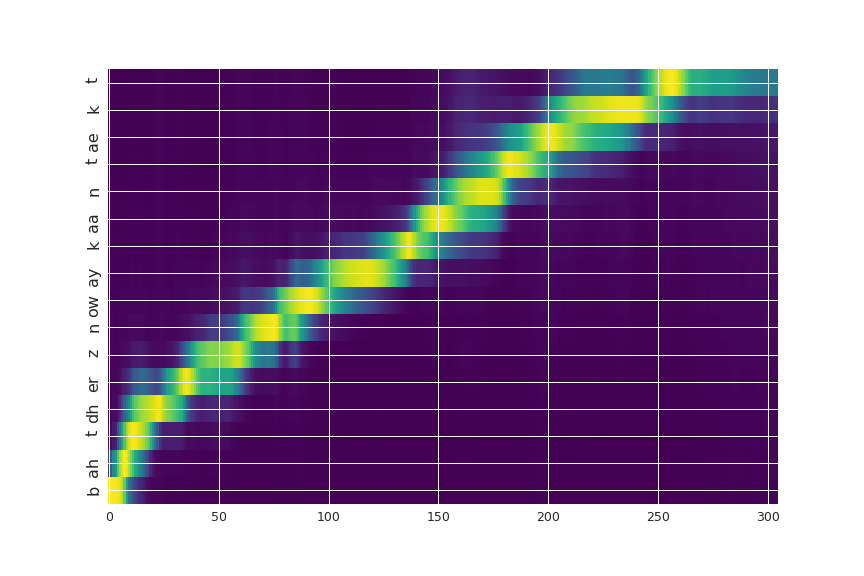

图例:X轴是输出时间(声学样本)Y轴是输入(文本/音素)。左图是扬声器10,右图是扬声器14。
最后,还支持自由文本:```bash python generate.py --text“hello world”--spkr 1 --checkpoint models / vctk / bestmodel.pth
## SetupRequirements: Linux/OSX, Python2.7 and [PyTorch 0.1.12](http://pytorch.org/). Generation requires installing [phonemizer](https://github.com/bootphon/phonemizer), follow the setup instructions there. The current version of the code requires CUDA support for training. Generation can be done on the CPU.```bashgit clone https://github.com/facebookresearch/loop.gitcd looppip install -r scripts/requirements.txt
用于训练论文中模型的数据可以通过以下方式下载:
bash scripts/download_data.sh
该脚本下载并预处理VCTK的子集。该子集包含带有美国口音的扬声器。
使用Merlin对数据集进行预处理- 使用WORLD声码器从每个音频剪辑中提取声码器功能。下载后,数据集将位于子文件夹下data,如下所示:
loop data vctk norm_info norm.dat numpy_feautres p294_001.npz p294_002.npz ... numpy_features_valid
可以使用Kyle Kastner的以下脚本执行预处理管道:https://gist.github.com/kastnerkyle/cc0ac48d34860c5bb3f9112f4d9a0300。
Pretrainde模型可以通过以下方式下载:
bash scripts/download_models.sh
下载后,模型将位于子文件夹下models,如下所示:
loop data models blizzard vctk args.pth bestmodel.pth vctk_alt
更新10/25/2017:单一扬声器型号提供型号/暴雪/
最后,语音生成需要在Merlin中完成SPTK3.9和WORLD声码器。要下载可执行文件:
bash scripts/download_tools.sh
这导致以下子目录:
loop data models tools SPTK-3.9 WORLD
单一扬声器模型在暴雪2011上进行了训练。应按上述方式下载和准备数据。数据准备好后,运行:
python train.py --noise 1 --expName blizzard_init --seq-len 1600 --max-seq-len 1600 --data data/blizzard --nspk 1 --lr 1e-5 --epochs 10
然后,继续训练模型:
python train.py --noise 1 --expName blizzard --seq-len 1600 --max-seq-len 1600 --data data/blizzard --nspk 1 --lr 1e-4 --checkpoint checkpoints/blizzard_init/bestmodel.pth --epochs 90
在vctk上训练新模型,首先使用噪声级别4和输入序列长度100训练模型:
python train.py --expName vctk --data data/vctk --noise 4 --seq-len 100 --epochs 90
然后,在完整序列上使用2的噪声级继续训练模型:
python train.py --expName vctk_noise_2 --data data/vctk --checkpoint checkpoints/vctk/bestmodel.pth --noise 2 --seq-len 1000 --epochs 90
如果您发现此代码在您的研究中有用,请引用:
@article{taigman2017voice,
title = {VoiceLoop: Voice Fitting and Synthesis via a Phonological Loop},
author = {Taigman, Yaniv and Wolf, Lior and Polyak, Adam and Nachmani, Eliya},
journal = {ArXiv e-prints},
archivePrefix = "arXiv",
eprinttype = {arxiv},
eprint = {1705.03122},
primaryClass = "cs.CL",
year = {2017}
month = October,}Loop拥有CC-BY-NC许可证。
还没有评论,说两句吧!
热门资源

allennlp-server
allennlp-server Serve allennlp services as sep...

allennlp_extras
allennlp_extras Some utilities build on top of...

allennlp-speech
allennlp-speech

allennlp-dureader
An Apache 2.0 NLP research library, built on Py...

ETD_cataloguing_a...
ETD catalouging project using allennlp


智能在线
400-630-6780

聆听.建议反馈
E-mail: support@tusaishared.com

 资源分类
资源分类


